Review of Artificial Intelligence Adversarial Attack and Defense Technologies

这篇文章是深度学习中对抗攻击和防御的一个综述性文章(2019)。文章首先介绍了攻击在训练阶段和测试阶��段的实现方法。然后分别总结了对抗技术在 CV, NLP, 网络安全和在真实世界中的应用。最后还介绍了三类主要的对抗防御方法:修改数据、修改模型、使用辅助工具。另外还提出了一种用于生成对抗性文本样本的算法。
Abstract(摘要)
In recent years, artificial intelligence technologies have been widely used in computer vision, natural language processing, automatic driving, and other fields. However, artificial intelligence systems are vulnerable to adversarial attacks, which limit the applications of artificial intelligence (AI) technologies in key security fields. Therefore, improving the robustness of AI systems against adversarial attacks has played an increasingly important role in the further development of AI. This paper aims to comprehensively summarize the latest research progress on adversarial attack and defense technologies in deep learning. According to the target model’s different stages where the adversarial attack occurred, this paper expounds the adversarial attack methods in the training stage and testing stage respectively. Then, we sort out the applications of adversarial attack technologies in computer vision, natural language processing, cyberspace security, and the physical world. Finally, we describe the existing adversarial defense methods respectively in three main categories, i.e., modifying data, modifying models and using auxiliary tools. Review of Artificial Intelligence Adversarial Attack and Defense Technologies
Adversarial Samples and Adversarial Attack Strategies
对抗样本
对抗样本是论文 11 中首次提出的,指的是添加肉眼不可见的扰动,造成目标网络分错类(对于分类来说)。最典型的来说就是下面这张图:
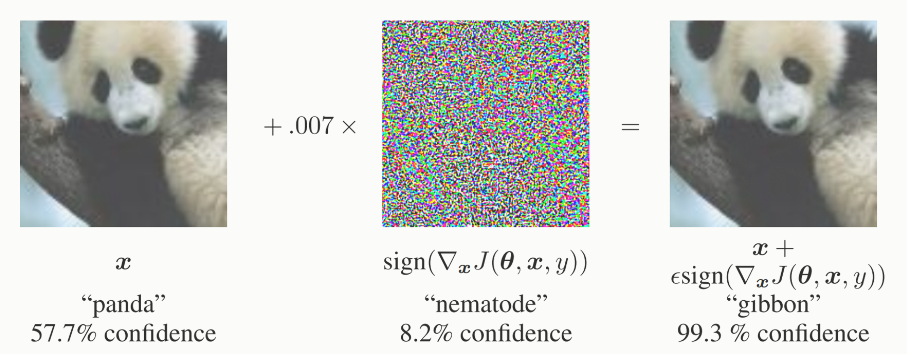
数学表达来说就是给定一个模型 ,以及输入 ,模型在攻击之前会将输入 分类到正确目标,即 ,而对抗样本 是输入 添加微小扰动之后使
对抗样本成因
论文 22 认为这是模型过拟合或者欠正则化导致模型对于未知数据的泛化能力不足造成的。也有论文 3 认为对抗样本是因为深度神经网络的高度非线性造成的。但是论文 4 设计了实验,对具有正则项以及具有线性性的网络中发现对于防范对抗样本的攻击并没有效果。他们认为这是因为高维空间中线性行为所导致的。一个典型的例子就是:
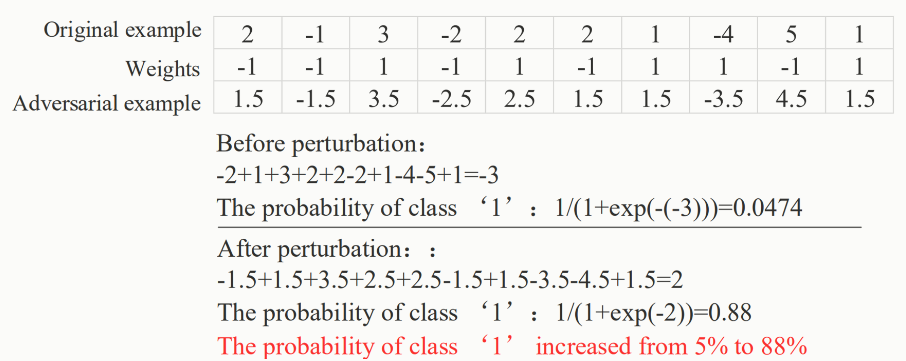
对于单个的像素的变动不会怎么变化,但是对于输入的所有维度进行小的扰动将会有显著的变化。所以 “ 攻击能力 ” 是因为多维度作用叠加的效果。
对抗样本的特征
可迁移性
对抗不稳定性,在经过变换(如旋转,平移等)之后将会失去攻击性。
指对抗学习
所以为啥叫 Regularization effect
Adversarial Capabilitise
攻击能力,因为攻击是攻击一个 “System”,根据我们能得到这个 “System” 的信息,我们有如下划分:
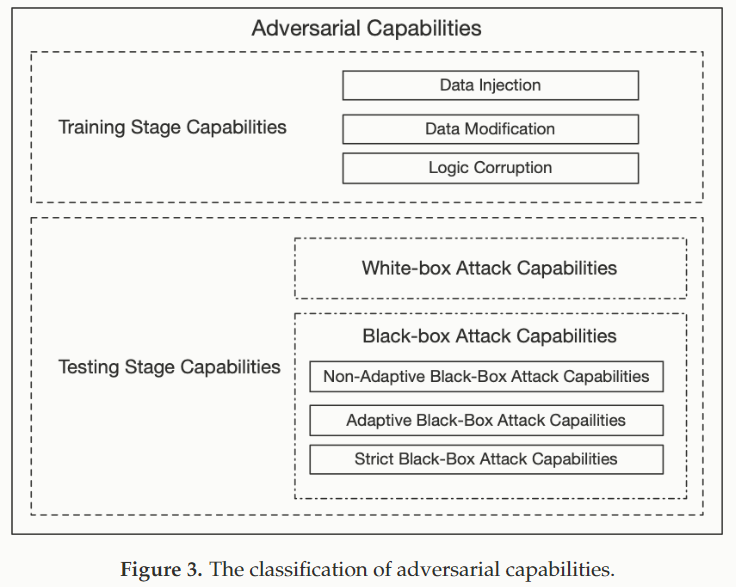
Training Stage Capabilities
在训练阶段的攻击一般是通过更改用于训练数据集来直接影响或者破坏目标模型。根据能力划分为:
在这种情况下,攻击者没有任何访问训练数据和算法的权限,但是有能力向训练数据集中添加新的数据。对手可以通过向训练数据集中插入对抗样本来达到攻击的目的
^8632f5
这种情况下,攻击者不能得到算法细节,但是可以完整得到数据集。并且可以修改数据来污染训练数据
^dce3c8
这种情况下,攻击者能够干扰目标模型的细节
^8cc058
Testing Stage Capabilities
在测试阶段的攻击主要聚焦于如何让模型识别错误,而不是篡改目标模型。此外攻击的效果一般取决于得到目标网络的信息量。
假设我们有被攻击网络 ,以及有从分布为 的训练样本对 (pair) ,以及随机种子 。则一个训练得到网络参数的过程可以被 formal 为
White-box Attacks
在白盒攻击模型中,攻击者知道被攻击的模型 全部知识,包括训练方式 ,数据分布 ,模型参数 。攻击者可以利用可用的信息识别目标模型 最容易攻击的特征空间,然后利用对抗样本生成达到攻击的目的。
Black-box Attacks
在黑盒模型的攻击中,攻击者对于目标模型 没有任何了解。这种攻击模式会通过 “ 过去 ” 的输入/输出 pair 来分析模型的漏洞。那黑盒模型的攻击又分为下面几种:
对于这种攻击模式。攻击者只能访问目标模型 的训练数据分布 。因此,攻击者可以利用一个代理模型 ,在来自数据分布 的样本下利用 训练过程得到一个 模型来近似目标模型 。然后攻击者就可以利用白盒攻击策略来攻击了
在这种攻击模型下,攻击者无法访问目标模型的任何信息。但是可以通过利用模型输入 以及网络输出标签 ,然后攻击者查询目标模型得到样本对 ,然后同样的转化为白盒模型进行攻击
与 Adaptive Black-Box Attack 类似,但是不一样的是它不是自适应的??什么意思
Adversarial Goals
对于攻击的效果来说,可以划分为下面四种:
降低目标模型对于某一预测的置信度
分错类,就是把猫识别为除了猫以外的东西。
有目标的分错类,就是特化为分错为某一特定的类,比如猫识别为狗。
而这个是更加具体的分错类
Adversarial Attacks
Training Stage Adversarial Attacks
在训练过程中根据攻击者的能力有下面几种攻击方式:
改变 Label 的,对标签进行扰动,从随机分布中选择标签作为训练数据的标签
输入特征篡改,这种情况下攻击者可以捏造训练数据的标签和输入数据的特征。
Testing Stage Adversarial Attacks
White-Box Attacks
白盒攻击,攻击者知道目标模型的结构和参数,那论文 6 中提出了一个对抗攻击的框架,大致可以分为两个步骤,方向敏感性估计 (Direction Sensitivity Estimation) ==和扰动选择 (Perturbation Selection)==,如下图所示:
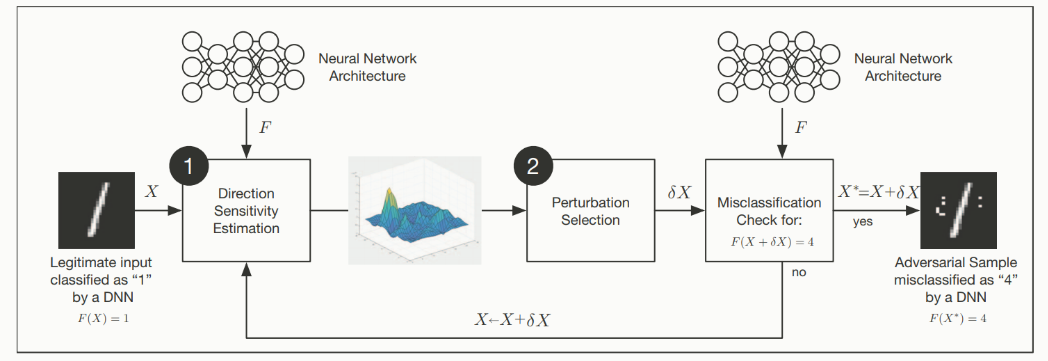
假设 是一个输入样本, 是训练好的 DNN 模型分类模型,攻击的目标是通过添加扰动 来生成一个对抗样本 ,使得:
攻击者通过搜索 数据流形 中样本 周围的方向,评估模型 对样本 每个特征方向的敏感性,与 重谈L1与L2正则#为什么 L1 更稀疏 中我觉得是有关联的。
扰动选择,然后攻击者利用敏感�信息来选择扰动 ,以获得最佳的扰动。
那注意每次添加扰动是叠加上去的,而并非从原始 进行添加。
另外,我们希望这个扰动尽可能小 (肉眼不可见),所以整个过程被描述为一个最优化问题:
即,寻找最小扰动 使得模型判断错误,但是这个公式是高度非线性,以及非凸的,很难找到适应解。
Direction Sensitivity Estimation
敏感方向估计通常是通过改变 输入来评估的,下面描述了当前的敏感方向评估技术;
L-BFGS
不知道这个 L-BFGS 是不是拟牛顿梯度下降法的那个 BFGS,简单来说就是由于上述公式高度非凸,所以论文 11 中转而解决一个弱化的问题,即找到一个使得最小化损失函数的添加值,从而将问题转化为凸优化问题。那缺点就是计算成本昂贵
Fast Gradient Sign Method(FGSM)
论文提出了一种快速梯度符号法,该方法的计算成本在于计算神经网络输入的梯度,对抗样本是通过下面公式产生的:
在这里 是模型 的 ,在 正则化 文章中有所提及,这里不在赘述。 是对于具有正常标签 的梯度, 是控制扰动幅度的超参数。这是一种基于线性假设的近似。
- 什么是线性假设?
- 为什么是近似?
One-Step Target Class Method
这是 FGSM 的一种变体,它最大化了某一个具体类别的 在给定样本 上的概率 ,对于具有交叉熵损失函数的模型,可以使用单步目标类别方法来生成对抗样本:
Basic Iterative Method(BIM)
这是对于FGSM方法的拓展,使用小步长多次应用FGSM :
这里 表示步长,这里的 是对于样本 的逐元素裁剪。那这种方法不依赖于模型近似,当模型迭代更多次时,会产生更多的对抗样本。
Iterative Least-Likely Class Method(ILCM)
得,再把上面的方法改成有目标的,就是新的 ILCM,
Jacobian Based Saliency Map(JSMA)
论文使用 矩阵找到敏感方向,该方法直接提供了输出分量相对于每个输入分量的梯度,并且所获得的知识用于复杂显著图方法生成对抗样本。该方法��通过对扰动的 范数进行正则,这意味着只需要修改图像的一些像素即可。
One Pixel Attack
单像素攻击,论文提出了一种极端攻击方法,可以通过修改图像中仅仅一个像素的值来实现攻击。他们使用差分进化算法 (Differential evolution algorithm),来迭代地修改每个像素,生成一个子图像 (sub-image),并根据选择标准保留最佳攻击效果的子图像,从而实现对抗攻击。
DeepFool
论文提出了一种基于迭代计算给定图像的最小 norm 的对抗扰动的方法,以便找到最接近样本 的决策边界,并且在边界上找到最小的样本。方法解决了 FGSM 中选择参数 的问题,并通过使用多个线性逼近来对抗非线性决策函数。这项工作生成的扰动比 FGSM 更小,并且具有类似的欺骗率
不太懂这里的 minimal norm 是什么?以及怎么样使用多个线性逼近对抗非线性决策函数?
HOUDINI
论文提出了一种名为 HOUDINI 的方法,它能够攻击基于梯度的机器学习算法。利用网络可微的损失函数的梯度信息生成干扰,不知道和上面基于梯度的算法有啥区别?
Perturbation Selection
扰动选择,攻击者评估目标模型在维度上的敏感度,从而确定最可能导致误分类的最小扰动。可以分为两类
Perturb All the Input Dimensions
扰动所有的输入维度,论文提出了一种方法来干扰每个输入维度,但是通过 FGSM 方法计算梯度符号方向的干扰量很小。
这种方法有效的减小了原始样本与相应对抗样本之间的欧几里得距离。
Perturb the Selected Input Dimension
论文选择了一个更加复杂的过程,包括显著性图,并只选择了有限数量的输入维度进行扰动。这种方法有效地减少了在生成对抗样本时对输入特征进行的扰动的量。
Black-Box Attacks
在前面我们提到了黑盒攻击的几种方式。non-adaptive 和 strict black-box 攻击不能访问到目标模型的内部结构和参数,但是可以通过访问目标模型的 API 接口来训练一个 local 的代理模型,该模型的决策边界近似目标模型的决策边界。
但是 adaptive 模式,攻击者同样不知道结构以及参数,还不能使用接口,但是可以观察到特定输入相应的输出,并通过将目标模型作为 oracle 查询来建立代理模型(这跟上面的有啥区别??)
Utilizing Transferability
利用对抗样本的可迁移性,论文中利用对抗样本的跨模型迁移性进行了黑盒攻击,这种方法通过对抗生成的合成样本训练一个 local 的替代模型,并且使用这个替代模型来制作对抗样本。而论文使用了贪心启发式算法在查询 oracle 标签时优先考虑样本,以获得一个近似目标模型的决策边界的替代 DNN 模型
模型反推
论文尝试在黑盒模型下,尝试通过访问模型和名称来恢复面部图像��,但是模型反推攻击只能恢复与定义类的实际数据相似的少量原型样本。
模型窃取
论文提出了一种用于提取模型的方法。攻击者可以构建一个 local 模型,攻击者通过 ML-API 返回的置信度与标签来恢复参数,由于攻击者没有任何有关模型的分布信息,因此攻击者可以查询 个随机维度的 维输入来解决数学上的未知参数。从而得到置信度和方程式的未知参数特征。
Adversarial Attack Applications
Computer Vision
Image Classification
已经有很多工作了
Semantic Segmentation and Object Detection
论文将对抗攻击扩展到了更困难的语义分割和目标检测领域,作者认为,分割和检测是基于图像中每个像素的密集预测。基于这种想法,他们提出了一种名叫密集对抗生成(Dense Adversary Generation,DAG),另外这种方法对不同的任务;不同的模型具有迁移性。
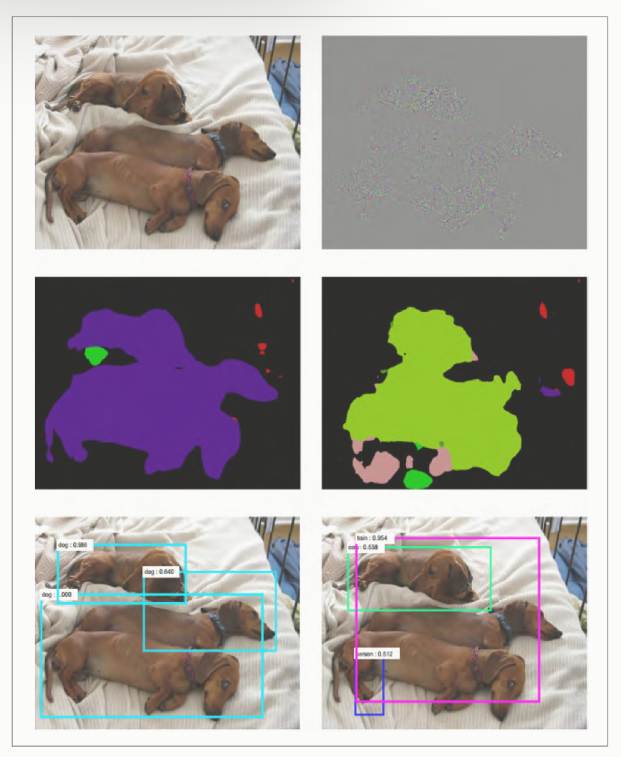
另外论文中提出了一种基于语义分割中空间背景信息来表征对抗样本的方法。此外这种攻击样本没有迁移性。
另外论文中提出了一种基于 GAN 的方法来生成对抗图像和视频,并且具有可迁移性
Natural Language Processing
Text Classification
论文提出一种基于字符级卷积神经网络对抗文本样本的算法,他们指出直接使用 FGSM 等算法产生对抗文本样本的问题,即输出的结果都是乱码,很容易被人眼识别出来。
他们使用了共享的 TextFool 代码生成对抗性文本样本,主要思想是通过同义词和拼写错误来修改文本样本中的现有单词。
另外也有论文使用选定的单测插入符号可以欺骗分类器。
最后有论文提出了一种修改原始样本生成对抗性样本的新方法。这种方法通过删除或者修改文本中的重要或突出单词,并将新单词引入样本来达到攻击的目的。
Machine Translation
论文表明,NMT(Neural Machine Translation) 对随机字符操作过于敏感,他们使用一个黑盒启发式来生成字符对抗样本。
Cyberspace Security
Cloud Service
论文在
Malware Detection
恶意软件分类
Intrusion Detection
入侵检测,论文提出了对软件定义网络 SDN 的深度学习检测系统进行了对抗攻击。
Attack in Physical World
Spoofing Camera
Road Sign Recognition
Machine Vision
Face Recognition
Defense Strategy
防御策略
Modifying Data
Adversarial Training
Gradient Hiding
Blocking the Transferability
Data Compression
Data Randomization
Modifying Model
Regularization
Defensive Distillation
防御蒸馏