Word Embedding
· 3 min read

info
在谈到 Embedding 不得不谈到 Word Embedding
单词的表达
One Hot Representation
类似于图像分类任务中的 One Hot 编码,我们可以对于单词施行 One Hot Representation.
实例
有 1000 个词汇量。排在第一个位置的代表英语中的冠词 “a”,那么这个 “a” 是用 ,只有第一个位置是 1,其余位置都是 0 的 1000 维度的向量表示,如下图中的第一列所示。
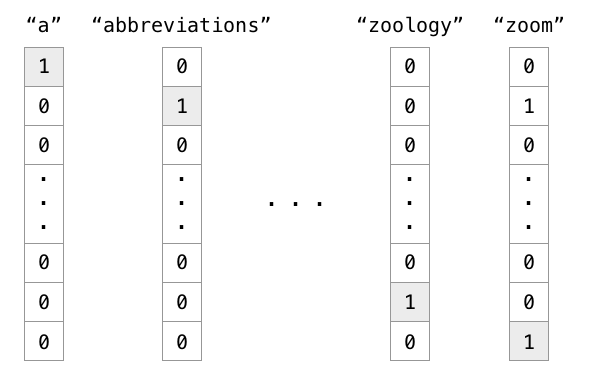
也就是说,
info
One Hot 编码的每个单词就是一个维度,每个单词之间是 independent 的
Distributed Representation
但是上面的编码方式很稀疏,丧失了单词之间的联系,有没有一种编码方式能够隐式的嵌入单词之间的关系?
考虑这样的表格:
| 0 | 1 | ||
|---|---|---|---|
| 0 | gender | female | male |
| 1 | age | child | adult |
这个表格中的 , 可以视为 “ 特征 “,而 则是该特征的特征值
我们手动寻求这四个单词之间的关系 ,然后可以使用在两个特征上的值去表示四个单词
info
但是就如图像处理中的各种 一样(如,),我们在 中采用了卷积核用来自动 ” 提取特征 “;是不是我们可以在这里采用同样的思路。
Word Embedding
info
Word Embedding 就是要从数据中自动学习到输入空间到 Distributed representation 空间的映射
那一个非常粗暴的方式是什么呢,我直接学一个矩阵,假设输入词汇量 ,想要提取出 个特征,那我学一个 的转换矩阵就好。
训练
我们预先是不可能知道这个转换矩阵是怎么样的,下面有两种方法。
- 从各个输入 之间的关系找目标。如聚类
- 接下游任务。我们的 Embedding 网络就是需要学习 ,那我们给定数据 ,我们可以去学习一个 ,这个网络由两个部分构成 ,以及 ,于是等到网络训练完毕,则自然学到了映射
tip
这里类比图像中的各个任务,Embedding 层就类似于 Backbone,而文字的下游任务可以是单词情感等
 (几种不同的任务)
(几种不同的任务)
像啊,很像啊
上面说到的后两种任务,有很熟悉的味道。何凯明大佬的 1,与这个是什么关系,似乎叫掩码自编码