假设有数据:
X=(x1,x2,⋯,xN)T=x1Tx2T⋮xNT=x11x21⋮xN1x12x32⋮xN2……⋱…x1px2p⋮xNpN×P
其中 xi∈Rp,xi∼N(μ,Σ),参数为 θ=(μ,Σ)
单变量高斯分布
对于单变量的高斯分布 N(μ,σ2),即 p=1,其概率密度函数为
p(x)=2πσ1exp{−2σ2(x−μ)2}
我们希望通过观察到的数据来计算参数 θ 的值,使用 极大似然估计 进行估计,似然函数可以写为
logp(X;θ)=logi=1∏Np(xi;θ)=i=1∑Nlogp(xi;θ)=i=1∑N[log2π1+logσ1−2σ2(xi−μ)2]
求解参数
对于 μ 的估计实际上就是:
μMLE=argμmaxlogp(X;θ)=argμmaxi=1∑N−2σ2(xi−μ)2(省略无关项)=argμmini=1∑N(xi−μ)2对其求导得到:
∂μ∂i=1∑N(xi−μ)2=i=1∑N2⋅(xi−μ)⋅(−1)=0解得:
i=1∑NxiμMLE=i=1∑Nμ=N1i=1∑NxiσMLE2=argσmaxlogp(X;θ)=argσmaxi=1∑N[logσ1−2σ2(xi−μ)2]求导得:
∂σ∂logp(x;θ)=i=1∑N−σ1−21(xi−μ)2(−2)σ−3=0解得:
i=1∑Nσ2=i=1∑N(xi−μ)2σMLE2=N1i=1∑N(xi−μ)2而这里是含 μ 的,所以是 μMLE.
σMLE2=N1i=1∑N(xi−μMLE)2 无偏性
无偏估计就是 E(x^)=x,下面我们分别判断上述 μMLE,σMLE 的无偏性。
E[μMLE]=E[N1i=1∑Nxi]=N1i=1∑NE[xi]=N1Nμ=μ
可以化简一下 σ 的估计
σMLE2=N1i=1∑N(xi−μMLE)2 =N1i=1∑N(xi2−2μMLExi+μMLE2) =N1i=1∑Nxi2−2⋅μMLE⋅μMLEN1i∑Nxi+N1i=1∑NμMLE2 =N1i=1∑N(xi2−μMLE2)
于是期望是
E[σMLE2]=E[N1i=1∑N(xi2−μMLE2)]=E[N1i=1∑N(xi2−μ2)−(μMLE2−μ2)]=E[N1i=1∑N(xi2−μ2)]−E[(μMLE2−μ2)]=N1i=1∑NE[xi2−μ2]−E[μMLE2−μ2]=N1i=1∑NVar(xi)=σ2E[xi2]−μ2−E[μMLE2−μ2](Var(X)=E[X2]−E2(X))=σ2−E[μLE2−μ2]=σ2−E[μLE2]−E[μ2]=σ2−E[μLE2]−μ2=σ2−Var[μMLE]E[μLE2]−E2[μMLE]�=σ2−Var[N1i=1∑Nxi]=σ2−N21i=1∑NVar[xi](Var(CX)=D2Var(X))=σ2−N21Nσ2=NN−1σ2
所以,σMLE2 是有偏估计量,而且和真实值比较小,
而 σ^2=N−11i=1∑N(xi−μMLE)2 是无偏估计。
高维高斯分布
对于多变量的高斯分布 X∼N(μ,Σ),概率密度函数为:
p(X)=2π2p∣Σ∣211exp{−21(X−μ)TΣ−1(X−μ)}
其中,X∈Rp,
X=x1x2⋮xpμ=μ1μ2⋮μpΣ=σ11σ21⋮σp1σ12σ22⋮σp2⋯⋯⋱⋯σ1pσ2p⋮σppp×p
其中 Σ 一般为 半正定矩阵(This page is not published)。
马氏距离
(X−μ)TΣ−1(X−μ) 的计算结果是一个数,这个数被称为马氏距离。设我们有两个向量:
z1=(z11,z12)⊤,z2=(z21,z22)⊤
那么 z1 和 z2 之间的马氏距离为:
(z1−z2)TΣ−1(z1−z2)=(z11−z12z21−z22)Σ−1(z11−z12z21−z22)
显然,当 Σ−1=I 时,马氏距离等于欧氏距离 (z1−z2)TΣ−1(z1−z2)=(z11−z12)2+(z21−z22)2
这东西是个啥
这一坨东西表示了啥呢?
由于 Σ 是一个实对称矩阵,那么对 Σ 进行特征分解,那么有 Σ=UΛU⊤,并且 UU⊤=U⊤U=I,所以 U−1=U⊤,Λ=diag(λi)(i=1,2,⋯,N),并且 U=(U1,U2,⋯,Up)p×p
Σ=UΛUT=(U1,U2,⋯,Up)λ1λ2⋱λpU1TU2T⋮UpT=(U1λ1,U2λ2,⋯,Upλp)U1TU2T⋮UpT=i=1∑pUiλiUiT
而 Σ−1 是啥勒?
Σ−1=(UΛUT)−1=(UT)−1Λ−1U−1=UΛ−1UT
这里的 U 是正交矩阵,所以 U⊤=U−1
而 Λ 是一个对角线��矩阵,所以
Λ−1=diag(λi1),i=1,⋯,p
所以:
Σ−1=i=1∑pUiλi1UiT
那么代入到前面的马氏距离公式,
(X−μ)TΣ−1(X−μ)=(X−μ)Ti=1∑pUiλi1UiT(X−μ)=i=1∑p(X−μ)TUiλi1UiT(X−μ)
令 yi=(X−μ)⊤Ui,则上式可以变化为:
(X−μ)TΣ−1(X−μ)=i=1∑pyiλi1yiT=i=1∑pλiyi2
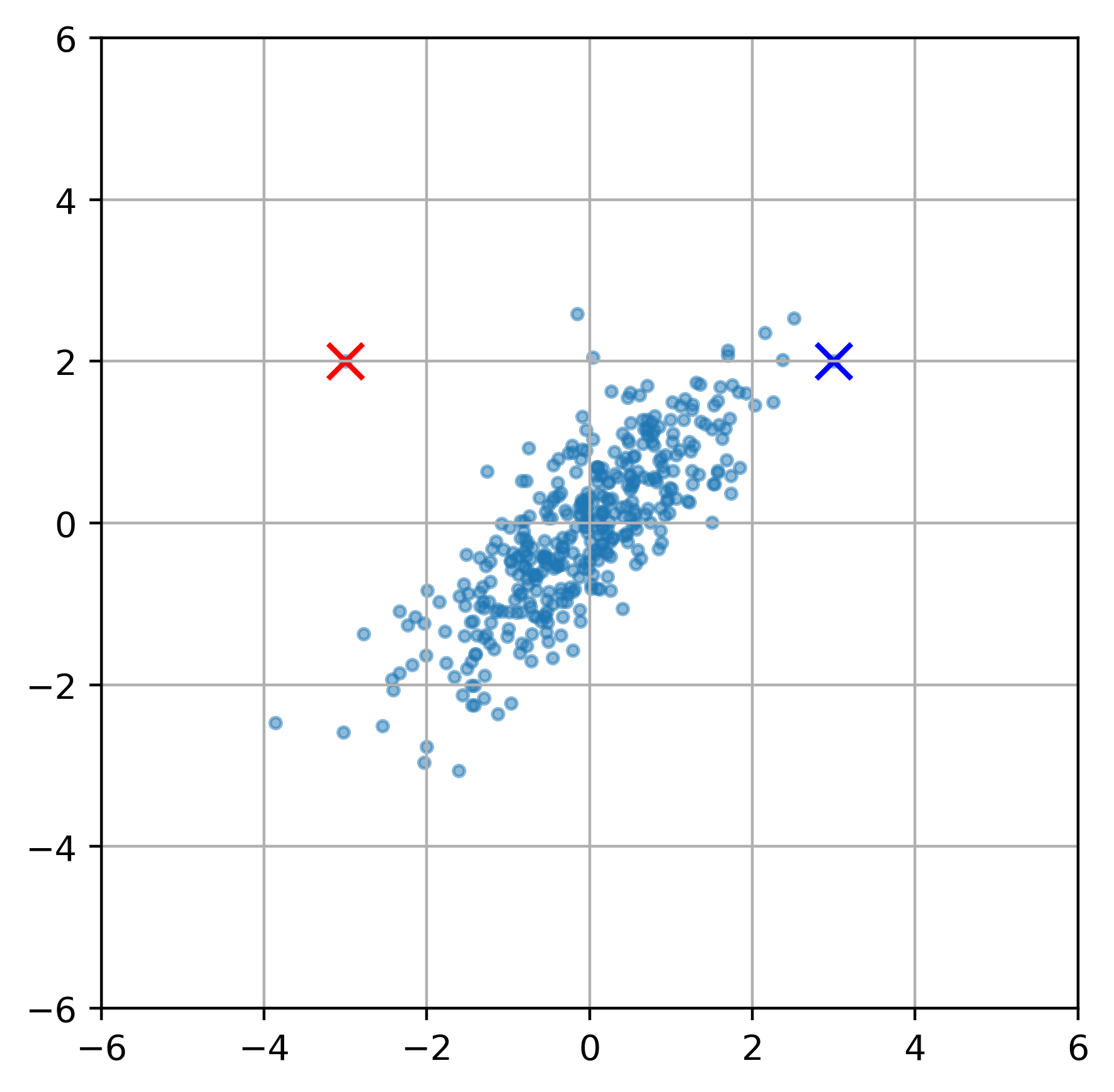
上图我们有红点和蓝点,他们与整个样本的 “ 中心 ” 的欧式距离都是一样的,但是马氏距离会怎么样呢?
首先我们先做变换 (X−μ)⊤Ui
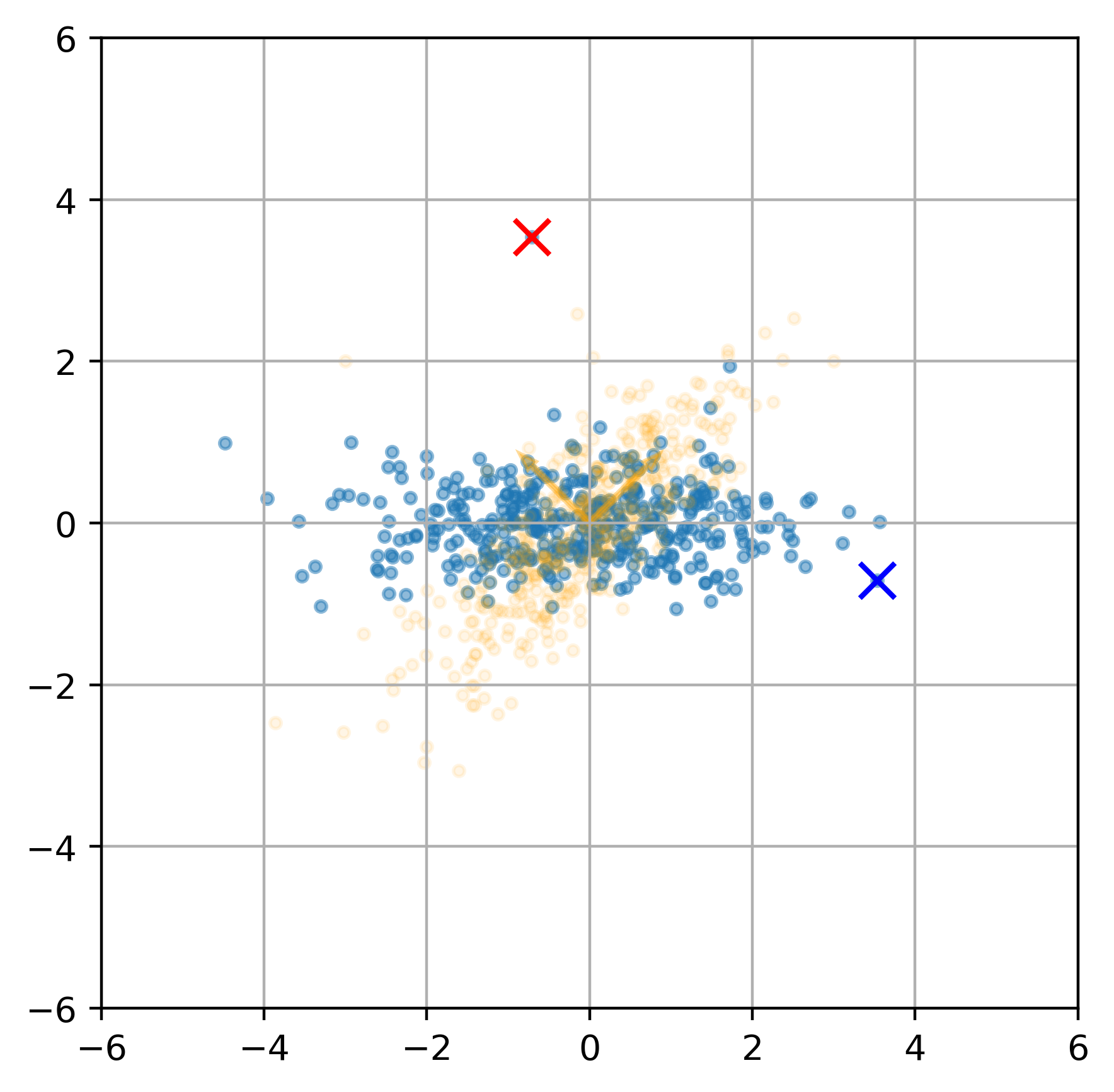 这个变换就是将样本先平移到原点,然后将原始的特征轴旋转成为主轴 (U 矩阵是正交矩阵)
这个变换就是将样本先平移到原点,然后将原始的特征轴旋转成为主轴 (U 矩阵是正交矩阵)
而之后 λiyi 实际上就是标准化
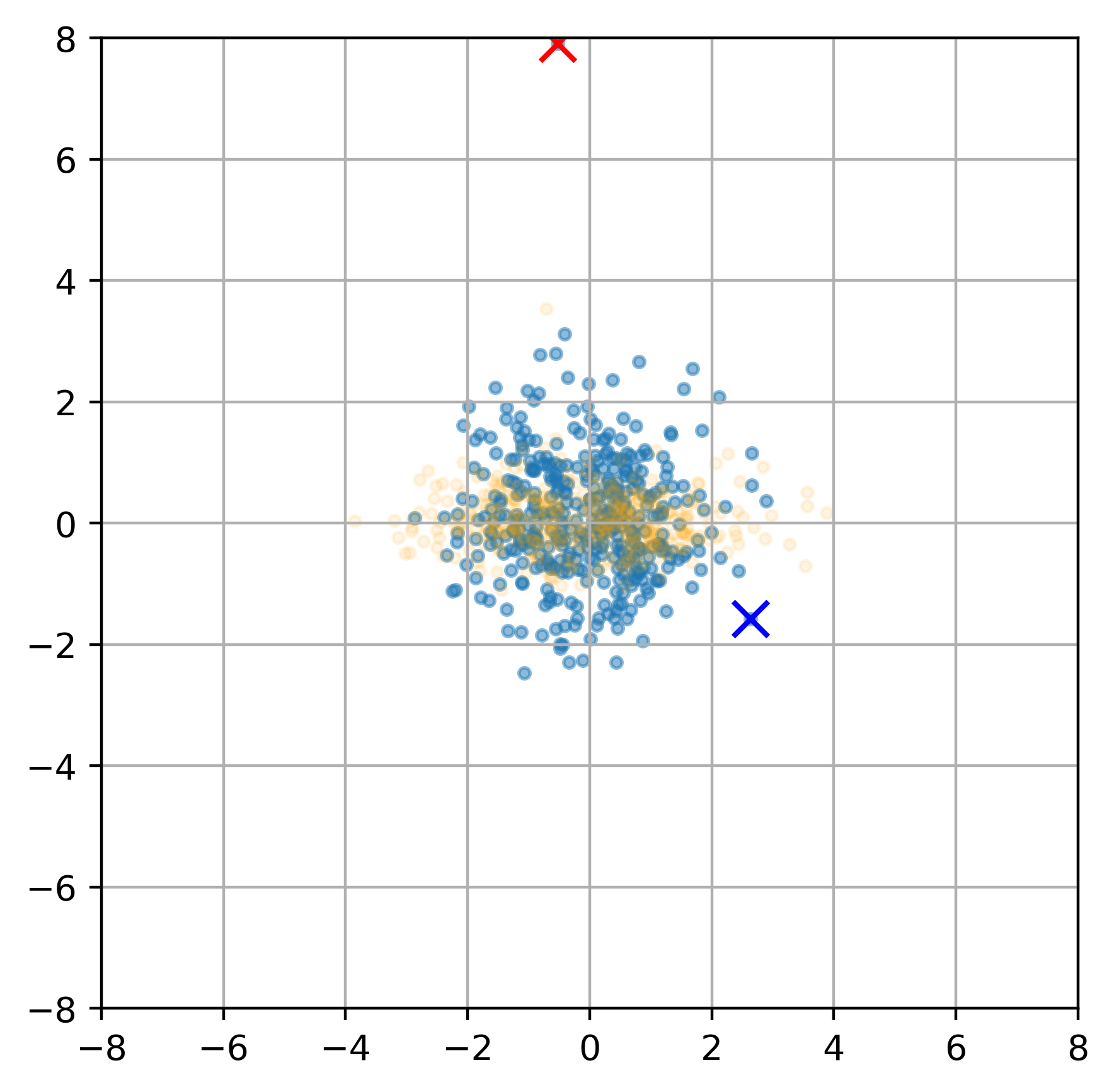 这样计算两个点的欧式距离就可以区分开了。
这样计算两个点的欧式距离就可以区分开了。
有主成分分析可知,主成分实际上就是特征向量的方向,而每个方向的方差就是对应的特征值,所以马氏距离就是 PCA+Norm
所以表达式 (X−μ)TΣ−1(X−μ) 实际上是在描述一个样本对于总体样本 “ 中心 ” 的距离,而概率密度函数
p(X)=2π2p∣Σ∣211exp{−21(X−μ)TΣ−1(X−μ)}前半部分是样本无关的,所以对于一个样本来说其概率与对总体样本 “ 中心 ” 的马氏距离负相关。
高维问题
由于 Σ 是一个 p×p 是对称矩阵,所以有 2p(p+1) 个参数。一旦输入维度过大,这个矩阵的计算会很复杂。所以有些时候会进行假设
可以假设其是对角矩阵,甚至在各向同性假设中假设其对角线上的元素都相同。前一种就是 Factor Analysis 后一种有概率 PCA:Principle Component Analysis(p-PCA)
单个高斯分布是单峰的,对于有多峰的数据分布肯定是不合适的,所以会有 混合高斯模型(GMM)
相关资料
